
개요계획새 인프라 및 DB 구축어플리케이션을 Target DB에 연결새 어플리케이션 실행 + DNS Record 변경DNS Record 변경 전파 대기기존 인프라 Takedown실행새 인프라 및 DB 구축GTID 기록스냅샷 기반 복제DB Replication 시작VPC PeeringSecurity Group Inbound RulesMaster-Slave Replication양방향 DB Replication 시작어플리케이션의 DB 커넥션 전환목적보안 그룹 설정어플리케이션 설정 수정, 배포Master-Slave 관계 역전새 어플리케이션 실행 + DNS Record 변경새 VPC에 어플리케이션 실행DNS Record 변경기존 인프라 TakedownDNS Record TTL + a 대기인프라 Takedown마치며Attachments
개요
빙글에서는 비용을 절감하고자 스타트업 크레딧을 받은 다른 계정으로 인프라 일체를 이전하게 되었다.
어플리케이션 서버는 그냥 만들면 그만이지만, DB는 데이터도 그대로 가져가야한다.
심지어 가져가는 동안에도 새 데이터가 생긴다.
어떻게 해야 달리는 자동차의 바퀴를 갈아끼울 수 있을까?

계획
인생이 계획대로 흘러가지는 않는다. 하지만 계획이 있어야 비슷하게라도 되지 않겠는가?
어떻게 하고 싶은지를 먼저 표현해보자.
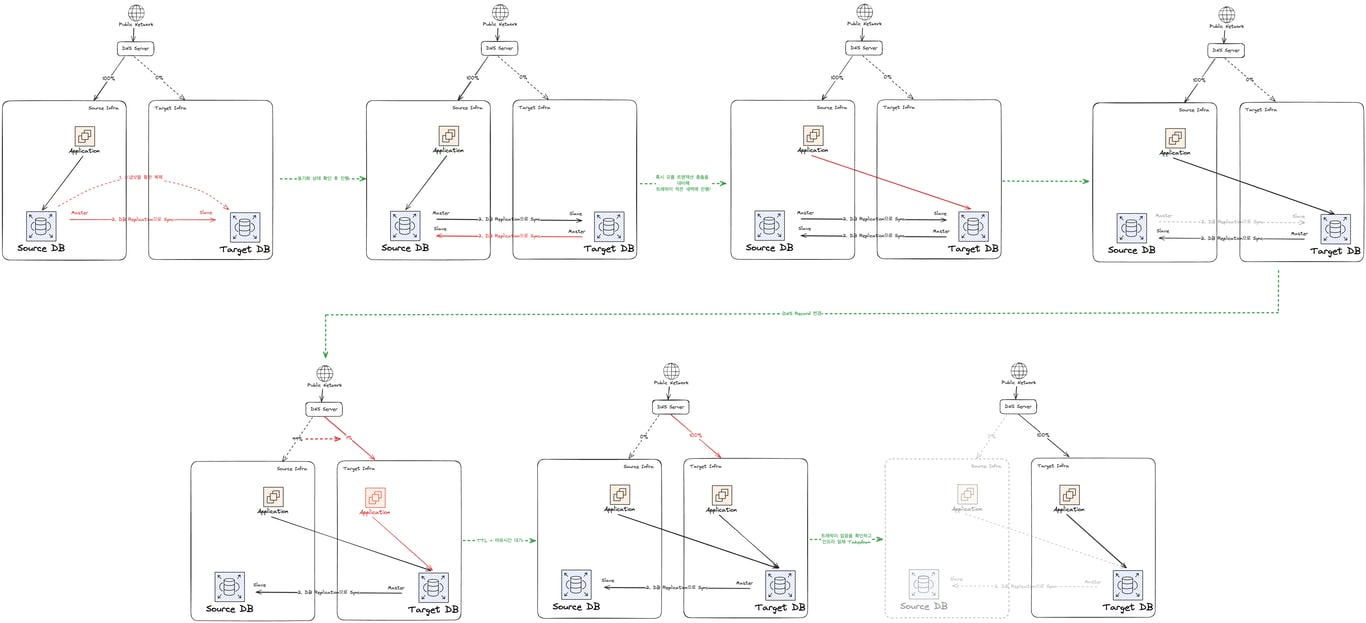
이런 과정을 꿈꾼다. 아래에서 자세히 다뤄보자.
새 인프라 및 DB 구축
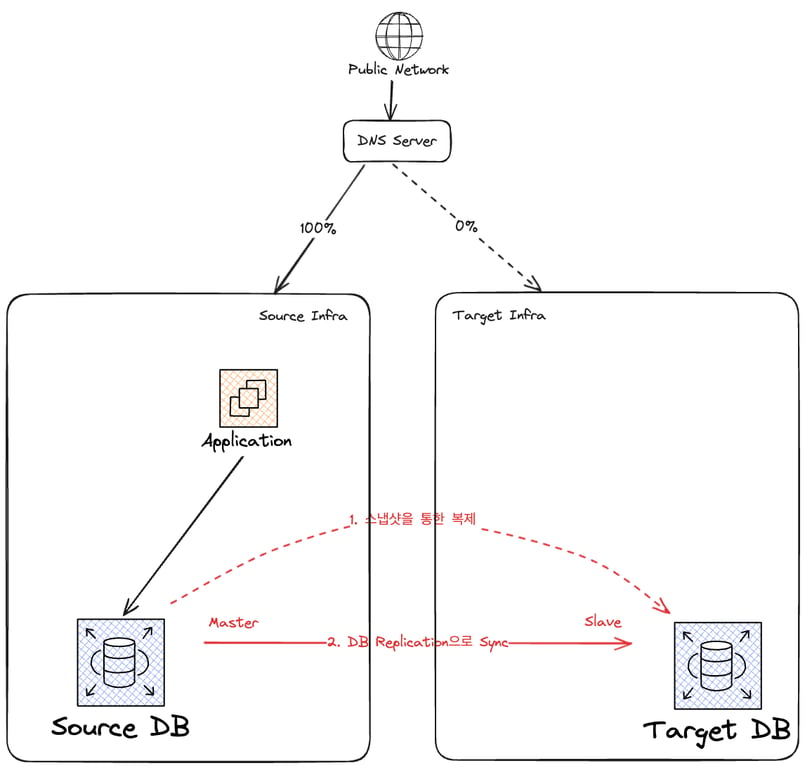
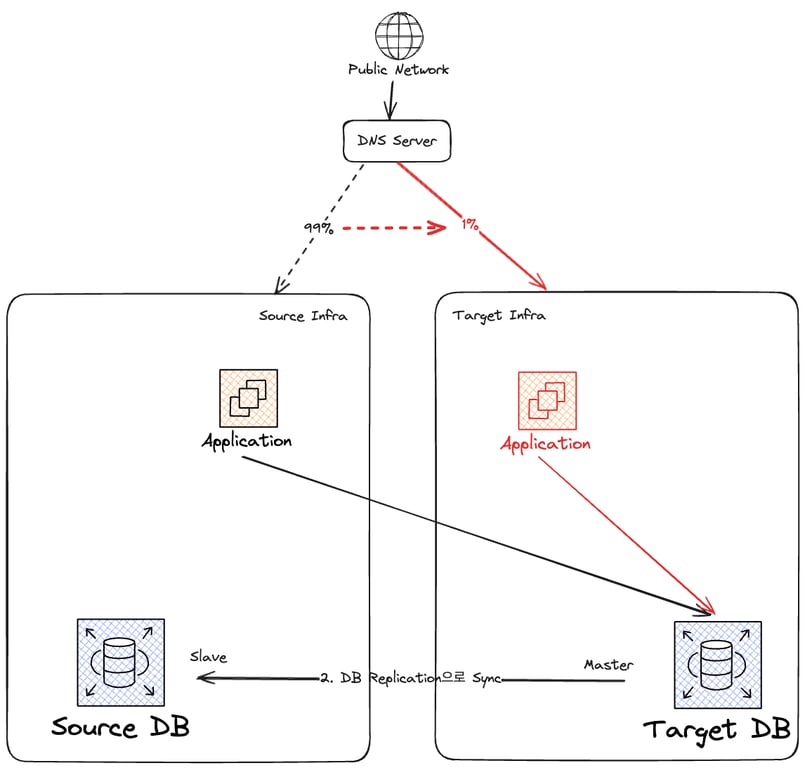
먼저 새 인프라(VPC)를 구축하고, 그 안에 DB를 구축한다.
기존 DB와 새 DB를 지금부터 각각 Source DB, Target DB라고 하겠다.
Source DB를 스냅샷을 통해 복제하여 Target DB를 만든다.
이후 DB Replication을 통해 두 DB를 동기화한다.
어플리케이션을 Target DB에 연결
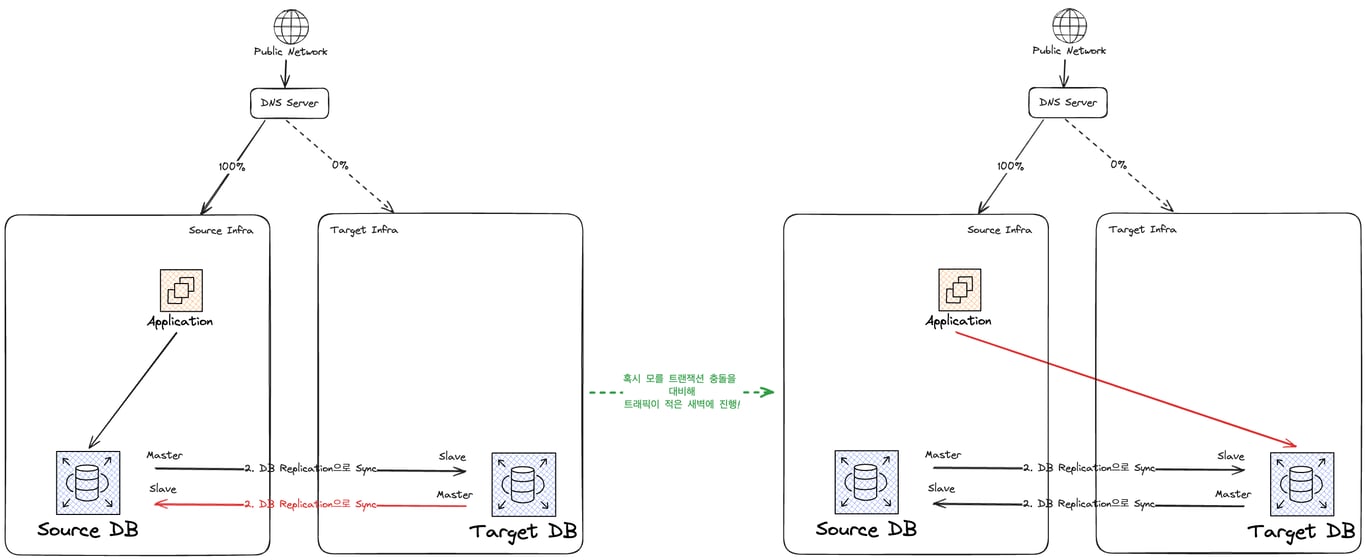
먼저 Source DB와 Target DB의 동기화 상태를 확인하고, Master-Master Replication을 건다.
이후 Source 인프라에서 트래픽을 받아주고 있던 Application을 Target DB에 연결하도록 조치한다.
기왕이면 영향을 줄이기 위해 트래픽이 적은 새벽 시간대를 활용하는 것이 좋겠다.
트랜잭션 충돌 등의 이슈를 최소화 할 수 있기 때문이다.
Target DB는 Slave 아닌가요?
원래는 Slave였으나, 반대 Master-Slave 관계도 추가했다.
이런 방식을 Master-Master Replication이라고 하는데, 서로가 서로의 Master이자 Slave가 되는 방식이다.
이 상태에서 같은 레코드를 동시에 수정하거나, auto_increment id를 통한 레코드 생성 등의 작업을 하면 두 트랜잭션은 충돌하게 된다.
그리고 트랜잭션 충돌이 발생하면 MySQL은 복제를 중단하게 된다.
DB를 다시 동기화하기 위해서는 사용자(관리자)가 손수 문제를 해결한 후 복제를 걸어주어야 한다.
하지만 여기서부터는 누가 Master인지가 모호해서 문제를 해결하기가 어려워진다. 심하면 DB 롤백이 필요할 수도 있다.
결론적으로 Master-Master Replication은 안전을 보장할 수 없다면 사용하지 않는 편이 좋다고 생각한다.
다중 어플리케이션이라면?
편의를 위해 단일 어플리케이션으로 표시했지만, 어플리케이션이 여러 개라도 목적은 같다.
모든 어플리케이션을 Target DB에 연결하는 것이다.
하지만 수단이 조금 달라져야 할 수 있다.
나는 위 과정을 무중단으로 처리하고자 Master-Master Replication을 사용했다.
단일 어플리케이션만을 사용하는 빙글의 경우, 트래픽 전환이 한순간이므로 트랜잭션 충돌 가능성이 낮다고 생각했기 때문이다.
안전을 보장할 순 없지만, 적어도 데이터가 사라지지는 않는다.
본인이 책임질 수 있는 수준이므로 직접 경험해봐야겠다고 생각했다.
하지만 다중 어플리케이션이라면, 사고를 책임질 수 없는 경우라면 얘기가 좀 다르다.
트래픽 전환이 길어지면 양쪽 DB에 트랜잭션이 발생하면서 충돌 가능성이 높아진다.
안전을 위해선 서비스를 중단하고 Master-Slave Replication만을 사용해 트랜잭션 충돌의 가능성을 막는 방법이 나을 것이다.
달리는 자동차의 바퀴를 갈아끼우는 건 까딱하면 대형사고다.
이렇게 대형사고의 리스크를 지고 서비스 중단 없이 마이그레이션하기 vs 서비스 5분 중단하고 마이그레이션하기, 어떻게 더 나을까?
이 정도 볼륨의 작업이라면 5분 중단을 택하는 것이 낫지 않을까?
그렇게 할 수 없다면, 기왕이면 트래픽이 적은 새벽에 하는 것이 좋겠다.
새 어플리케이션 실행 + DNS Record 변경
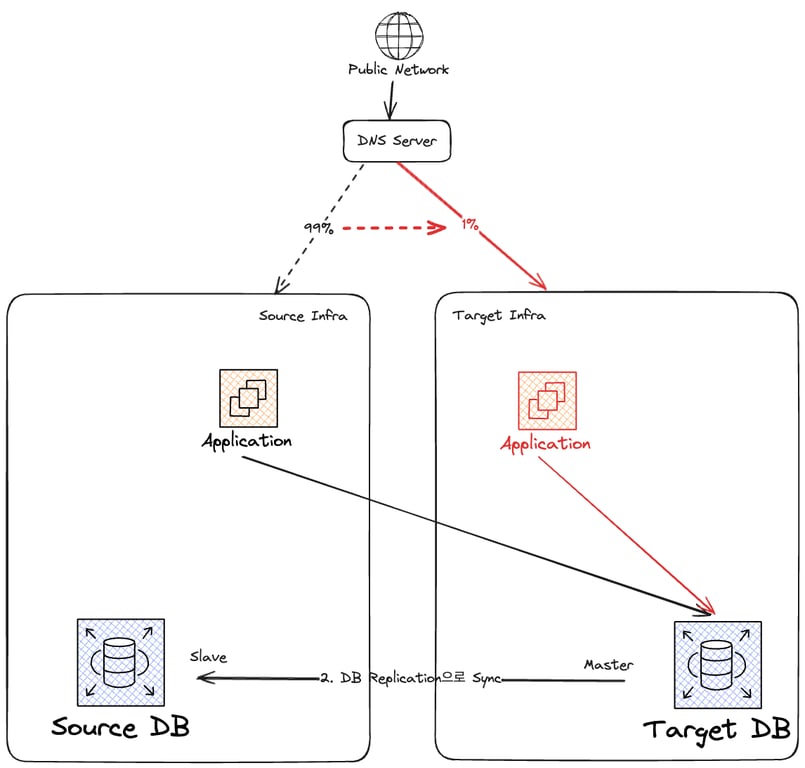
새 인프라에 트래픽을 받아줄 어플리케이션을 실행하고, 마찬가지로 Target DB를 가리키게 한다.
이후 DNS Record를 변경해 트래픽을 점진적으로 새 인프라로 옮긴다.
DNS Record 변경 전파 대기
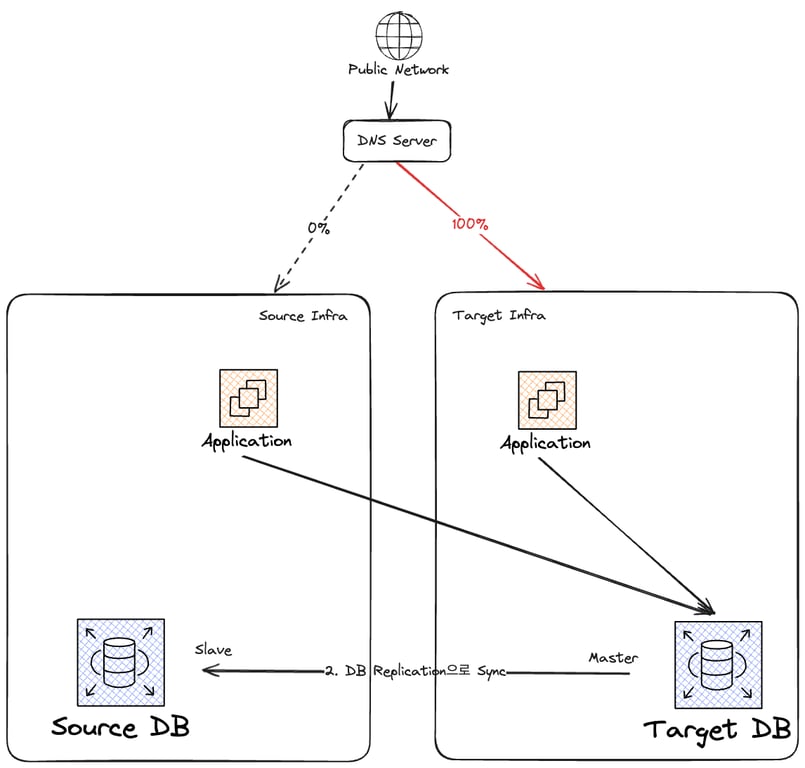
DNS Record가 완전히 전파되는데 걸릴 것으로 예상되는 시간은 최악의 경우 TTL만큼이다.
어떤 DNS Server나 Cache가 변경 전 1번 업데이트 되었다면, TTL 만큼 유지 후에 업데이트 할 것이다.
따라서 최대 TTL 만큼 걸릴 것으로 예상되나, 일부 DNS 서버는 TTL을 무시할 수도 있다.
급한건 아니므로 TTL 설정의 최대값인 72시간 정도는 기다려 주도록 한다.
기존 인프라 Takedown
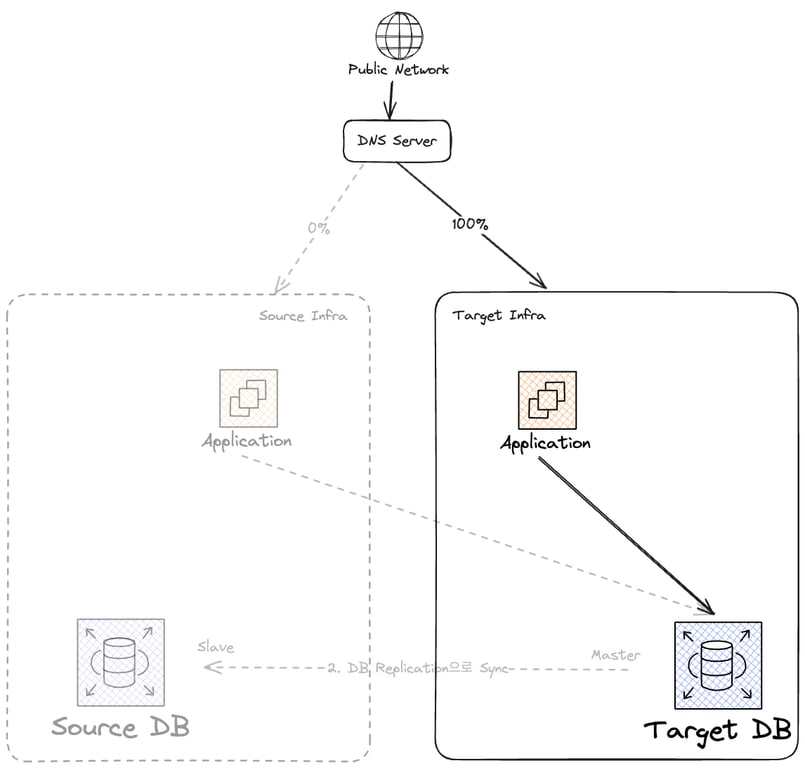
이제 더 이상 기존 Source 인프라로 들어가는 트래픽은 없(어야한)다.
트래픽을 잘 확인한 후 인프라 일체를 내려주자.
실행
말은 청산유수 비단장수 우리집에 금송아지가 100마리다.
실제로 한번 해보자. 과연 계획대로 될 것인가?
새 인프라 및 DB 구축
Binary log based replication? or GTID-based replication?

GTID-based replication을 권장하는 글을 많이 봤다.
Binary log based replication도 꽤 안정적이라고 알고 있는데, 왜?
MySQL 서버의 모든 변경 사항은 이벤트로서 바이너리 로그에 별도 기록된다.
DDL, DML, DCL 모두 말이다.
이렇게 바이너리 로그 파일은 복제 기능보다 우선하는 한 서버의 고유한 동작 기반이다.
따라서 복제 여부와 관계없이 파일 이름과 위치가 서버마다 다르다.
그러므로 복제를 할 때도 소스 DB의 바이너리 로그와 타겟(Replica) DB의 바이너리 로그는 파일명부터 다르다.
바이너리 로그 기반 복제는 소스 DB(Master)의 바이너리 로그의 파일명 및 커서 위치를 기반으로 이뤄진다.
때문에 장애 대응으로 Slave를 Master로 승격시키는 등 토폴로지 전환 시에 문제가 있다.
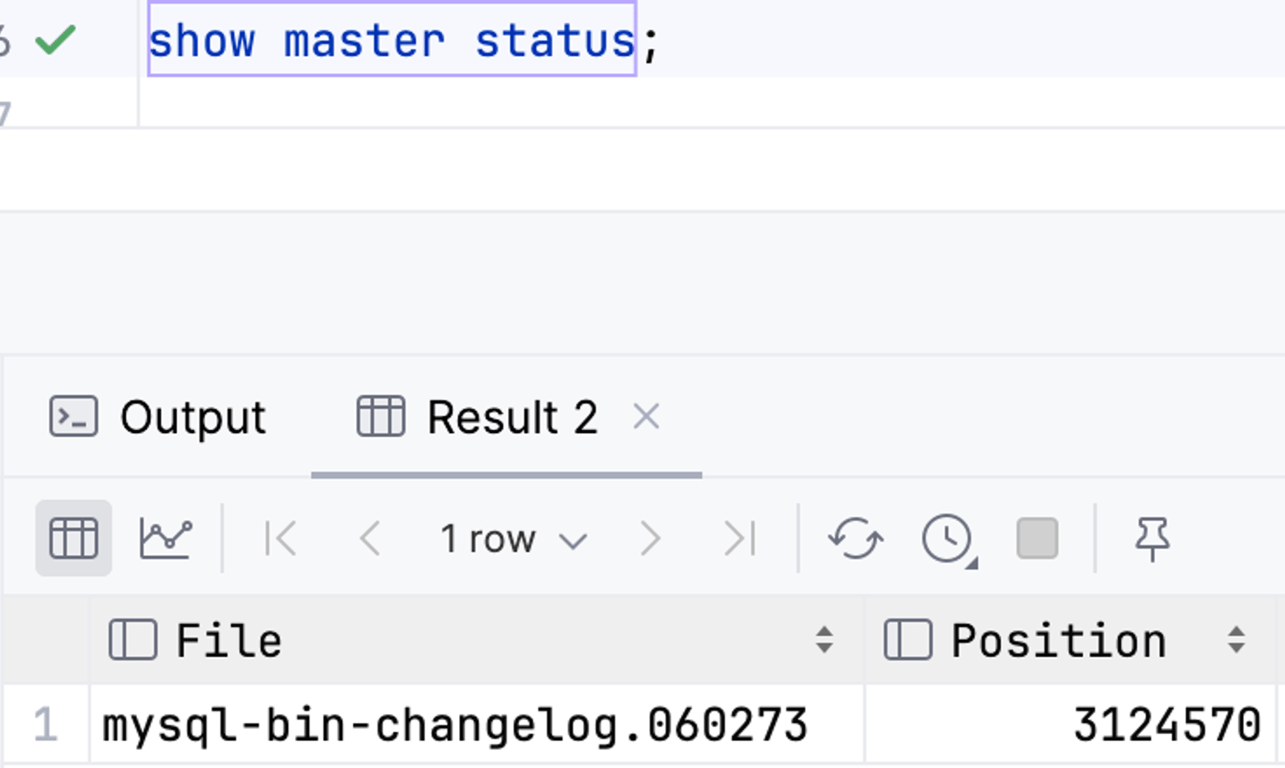
서버 1의
mysql-bin-changelog.059999, 237에 기록된 이벤트가 서버 2에서는 mysql-bin-changelog.099999, 3124570가 되는 등버전에 대한 기준—바이너리 로그 파일명, 커서 위치—이 서버마다 다르기 때문이다.
master의 최신 이벤트를 기준으로 failover를 하고 싶은데, 서버마다 이에 대응하는 이벤트를 찾아야 한다는 문제가 있다. (식별자가 없으므로 아마 찾기 어려울 것이다)
만약 이벤트를 식별하는 공통된 기준이 있다면 어떨까?
서버 1의
mysql-bin-changelog.059999, 237에 있는 이벤트에 server-1-event:1234라는 공통 식별자를 부여한다면, 이 이벤트는 서버 2에서도 server-1-event:1234로 동일하게 식별할 수 있다.비록 서버 2에서는
mysql-bin-changelog.099999, 3124570으로 기록된다고 해도 말이다.이렇게 트랜잭션(이벤트)에 대해 공통된 식별자를 부여하는 방법이 바로 GTID(Global Transaction Identifier)이다.
GTID가 있으면 장애 대응 상황에서 다음과 같이 문제가 간단해질 수 있다.
- without-GTID
각 서버마다 서버 1의mysql-bin-changelog.059999, 237과 대응되는 이벤트부터 각각 failover를 시작하면 된다
- with-GTID
server-1-event:1234부터 failover를 시행하면 된다
References

GTID-based 복제를 하려면 GTID를 미리 켜둬야 한다
Got fatal error 1236 from source when reading data from binary log: 'Cannot replicate because the source purged required binary logs. Replicate the missing transactions from elsewhere, or provision a new replica from backup. Consider increasing the source's binary log expiration period. The GTID set sent by the replica is '04d3b147-382e-11ef-890c-0272d300ff37:1', and the missing transactions are '67e173ac-a1ac-11ee-8578-028a3ca2d6a8:1-35''
스냅샷 생성은 GTID를 미리 켜준 후 진행되어야 한다.
스냅샷을 만든 후에 GTID를 켠다면 위와 같은 오류를 만날 수 있다.
원인은 스냅샷 생성 시작 시점과 GTID를 켜는 시점 사이의 공백 때문.
master-slave 간의 차이를 메꿀 수 없어 1236 오류가 발생한다.
MySQL 8.0 기준,
gtid_mode 및 enforce_gtid_consistency는 온라인으로 처리가 가능하므로 미리 켜주도록 하자.1236 오류가 뜨는 다른 오류도 있을 수 있는데, 바로 바이너리 로그의 회전이다.
expire_logs_days 가 설정되어 있으면 시간이 지나면서 바이너리 로그가 사라진다.따라서 위와 마찬가지로 원본과 복제본 간의 차이를 메꿀 수 없어 1236 오류가 발생한다.
이 외에도 다양한 원인이 있을 수 있지만, 내가 겪은 건 이 정도였다.
더 궁금하다면 1236 오류를 검색해보자.
GTID 기록
이제부터 복제를 통해 Replica DB를 구축할거다.
그러기 위해선 복제 시점의 GTID를 미리 기록해둬야 한다.
Git 브랜치를 떠올려보면 편할 것 같다.
덤프를 뜨는 순간, 덤프는 과거가 된다. 덤프 중에도, 이후에도 트랜잭션들이 있을 것이기 때문이다.
그래서 그 덤프로 Target DB를 복원했을 때, Source DB와 Target DB는 차이가 생기게 되며,
우리 DB는 어디서부터 복제를 시작해야 할지를 모른다.
그러므로 복제 시점의 GTID를 기록해놨다가 복원해줘야한다.
mysqldump를 사용할 때 --set-gtid-purged=ON 옵션을 사용하자.덤프파일 상단에 GTID 관련 쿼리가 포함되어 덤프에서 복원했을 때 GTID 정보도 함께 복원된다.
스냅샷을 사용한다면?
스냅샷을 기반으로 DB를 복제한다면 GTID 정보도 함께 복원된다. 그래서 별도 조치가 필요없다.
AWS RDS를 사용중이므로 RDS의 기능을 활용하는게 RDS 인스턴스 복원에 더 편리하다.
스냅샷 기반 복제
이제 스냅샷 기반 복제로 Target DB(Replica)를 만든다.
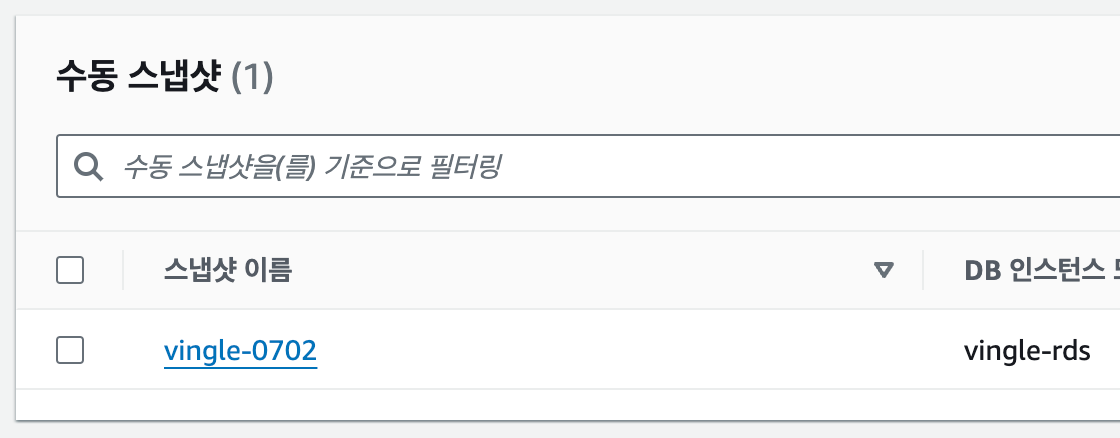
먼저 Source DB의 수동 스냅샷을 생성한다.
그러나 이대로 복제는 불가하다. 암호화된 스토리지의 스냅샷은 마찬가지로 암호화되어있기 때문이다.
따라서 공유 가능한 키로 스냅샷을 다시 암호화하는 과정이 필요하다.
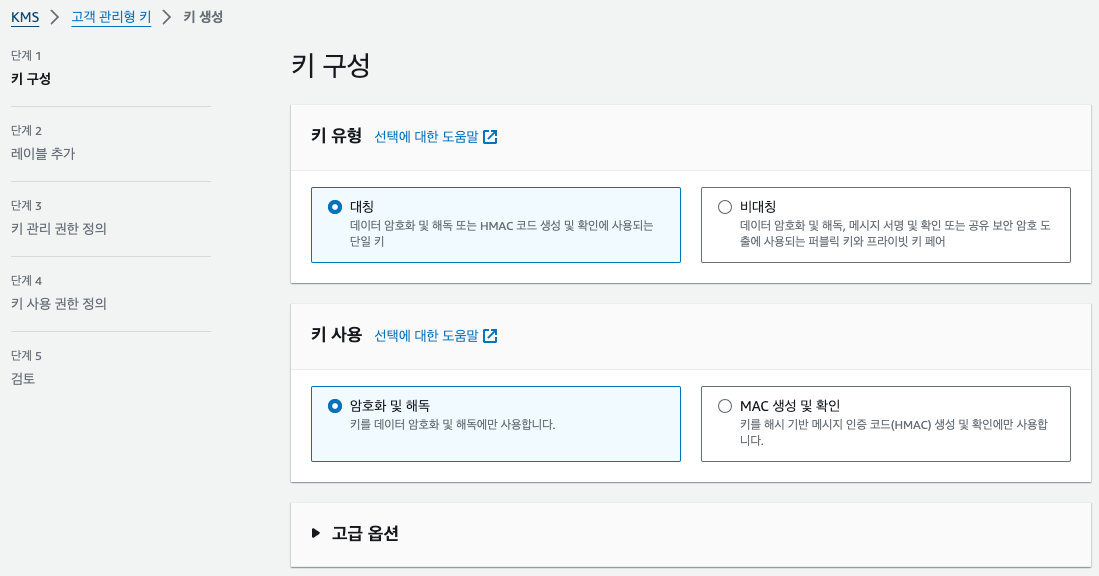
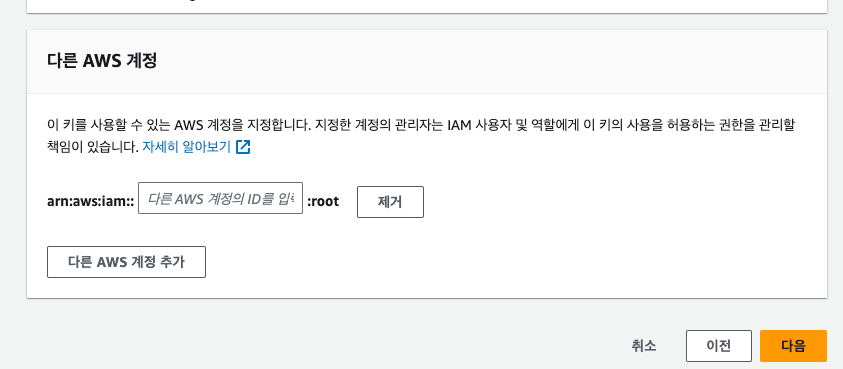
ARN 입력한 공유키를 통해 암호화가 다시 이뤄진다.
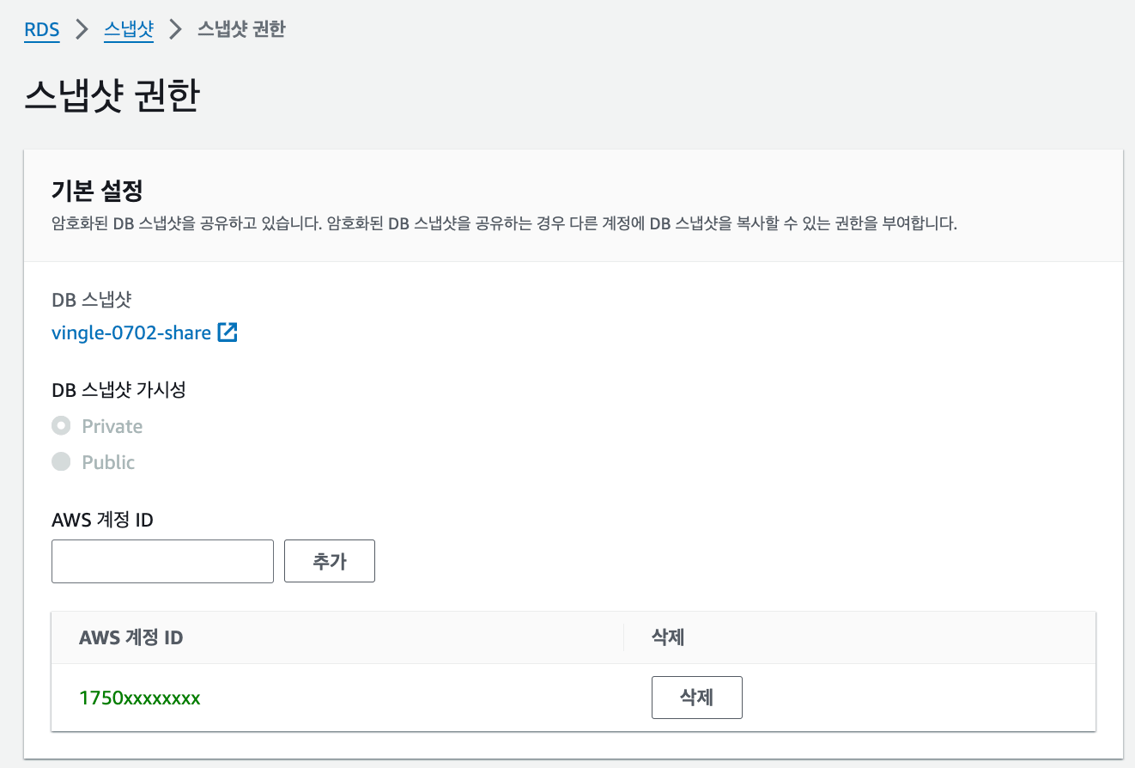
여기서부터는 Target 계정에서 진행한다.
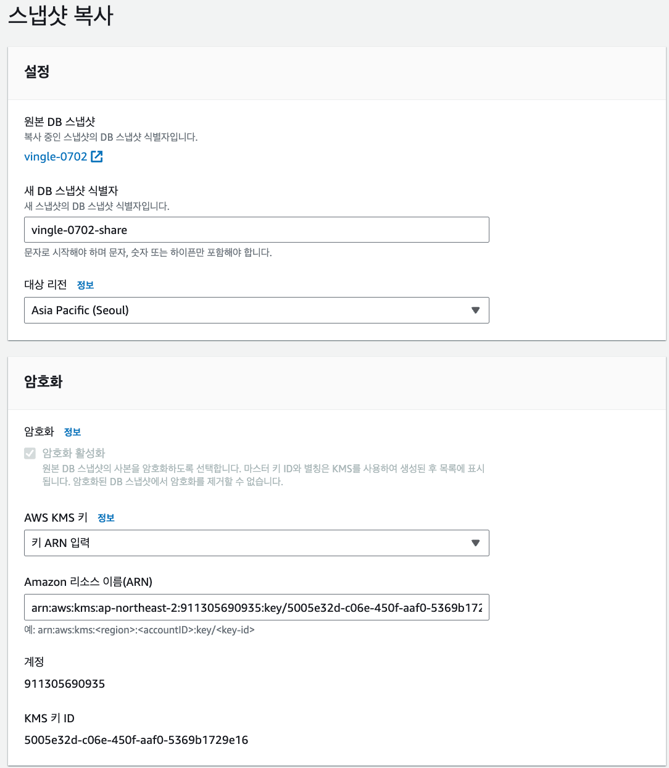
기존 계정과의 연을 끊기 위해, 바로 복원하는 것이 아니라 다시 복사한다.
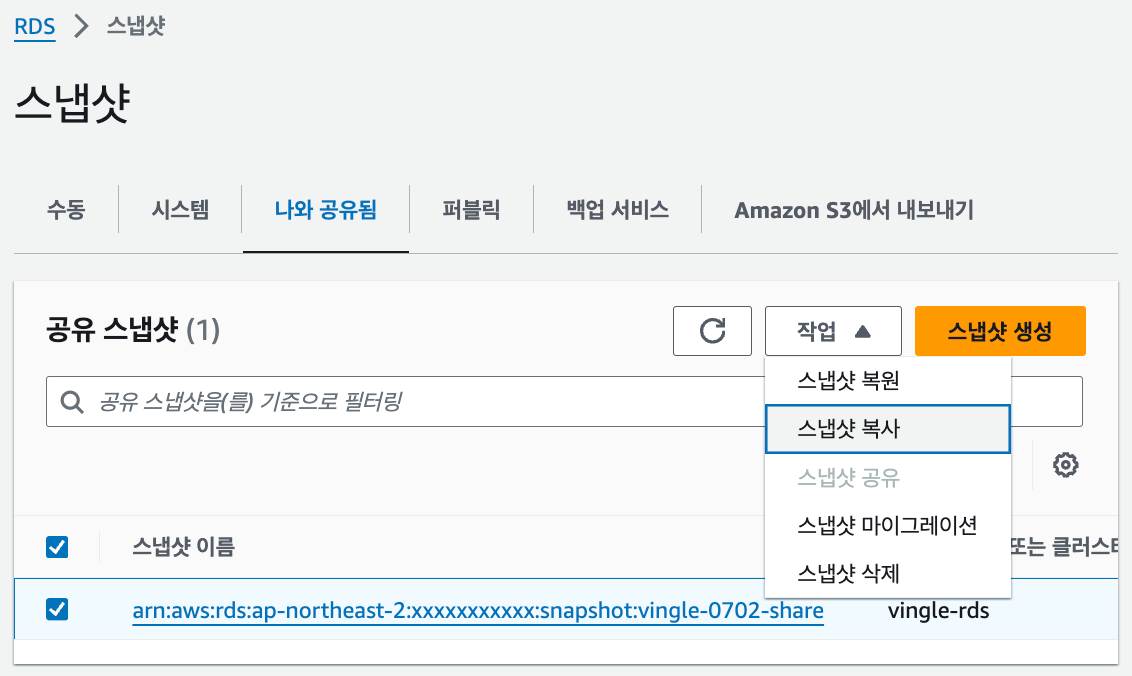
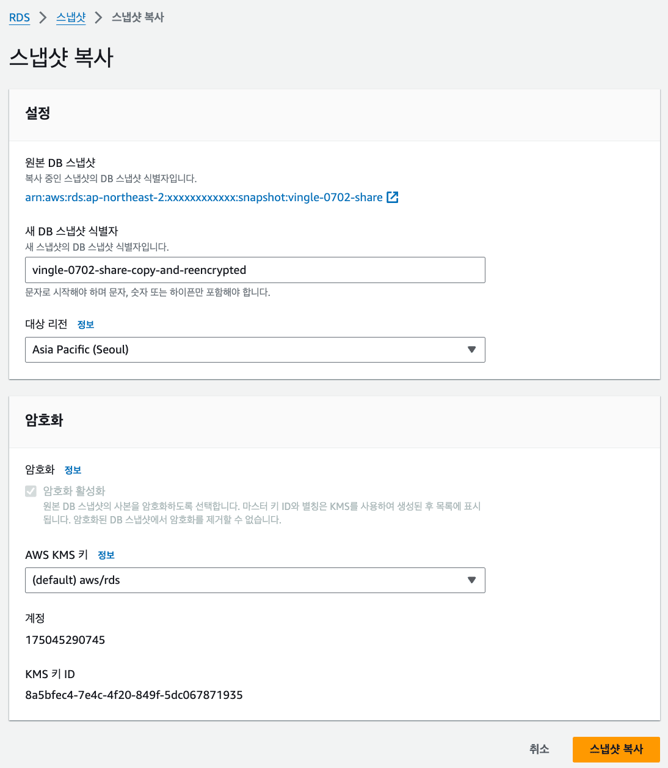
이 과정에서 암호화가 다시 이뤄진다.
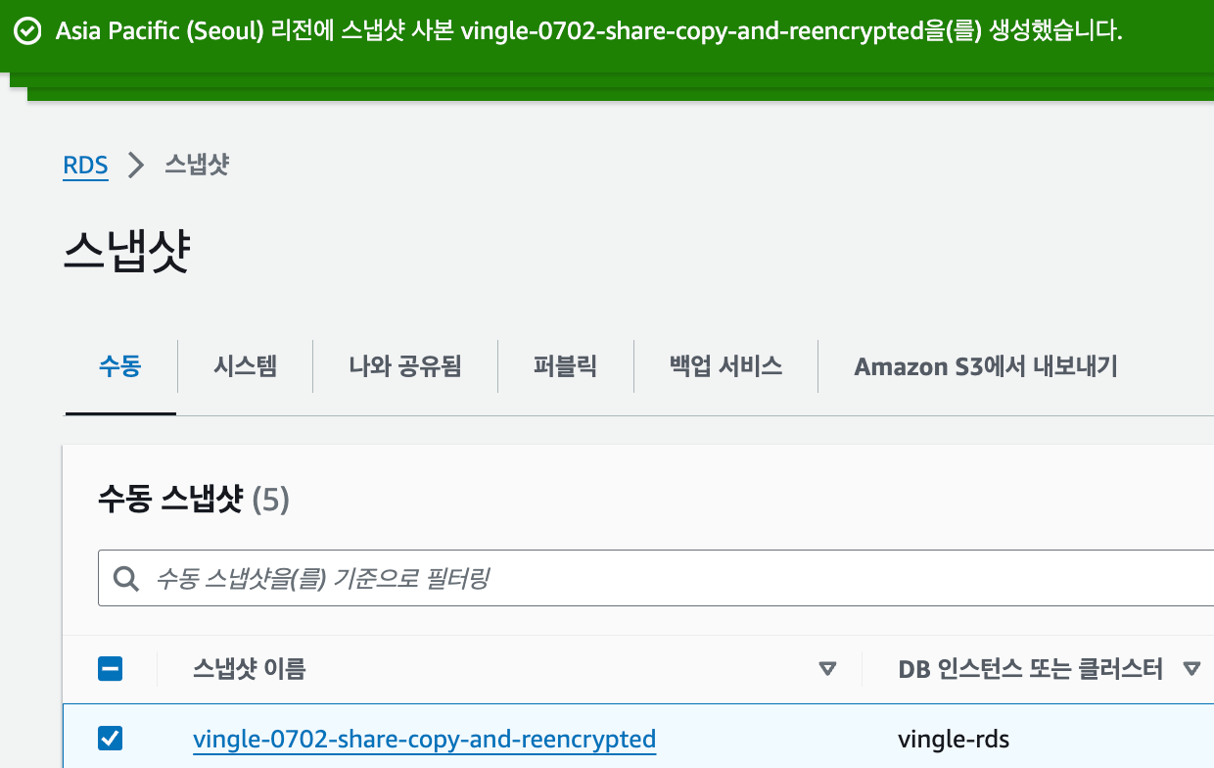
이상 보안상 복잡한 절차를 거쳤고, 마침내 스냅샷이 넘어왔다.
이 스냅샷에서 복원을 시켜주자.
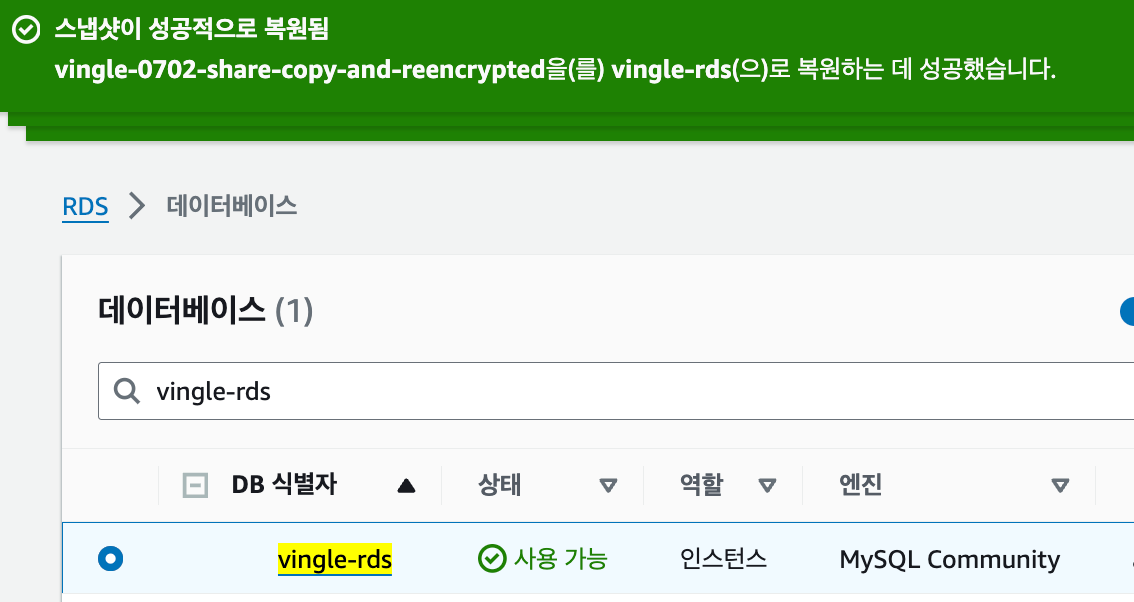
GTID 확인하기
Source DB 
Target DB(Replica)
그냥 궁금증에 GTID를 확인해봤다.
스냅샷을 생성하고 복원하는 사이에 트랜잭션이 더 진행된 모양이다.
GTID 덕분에 Target DB가
14340 이후부터 Replication 해야한다는 점이 명확하다.DB Replication 시작
Source ↔ Target DB 간에 Master ↔ Slave 관계로 Replication을 건다.
VPC Peering
이 과정에는 DB 간 연결이 필요한데, 본인은 이걸 VPC 피어링으로 해결해보려고 한다.
우선 DB를 외부로 노출하지 않아도 되므로 안전하고, 같은 AZ 간 내부 통신 비용은 무료이므로 1석 2조다.

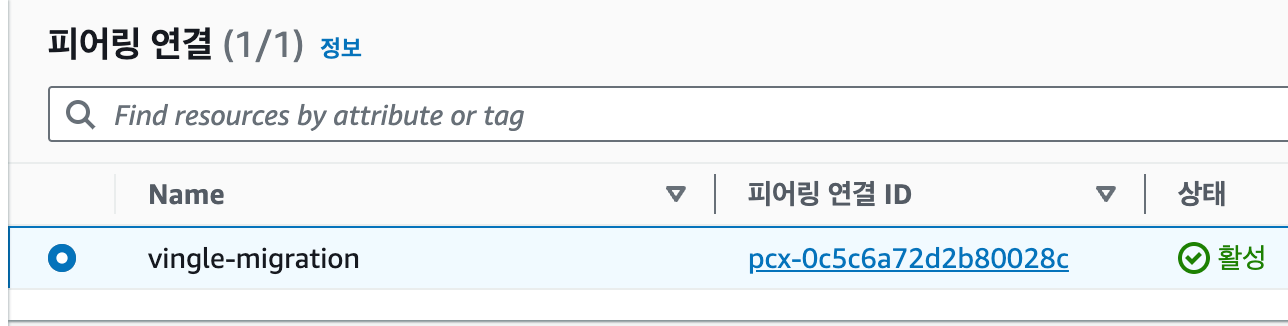
Security Group Inbound Rules
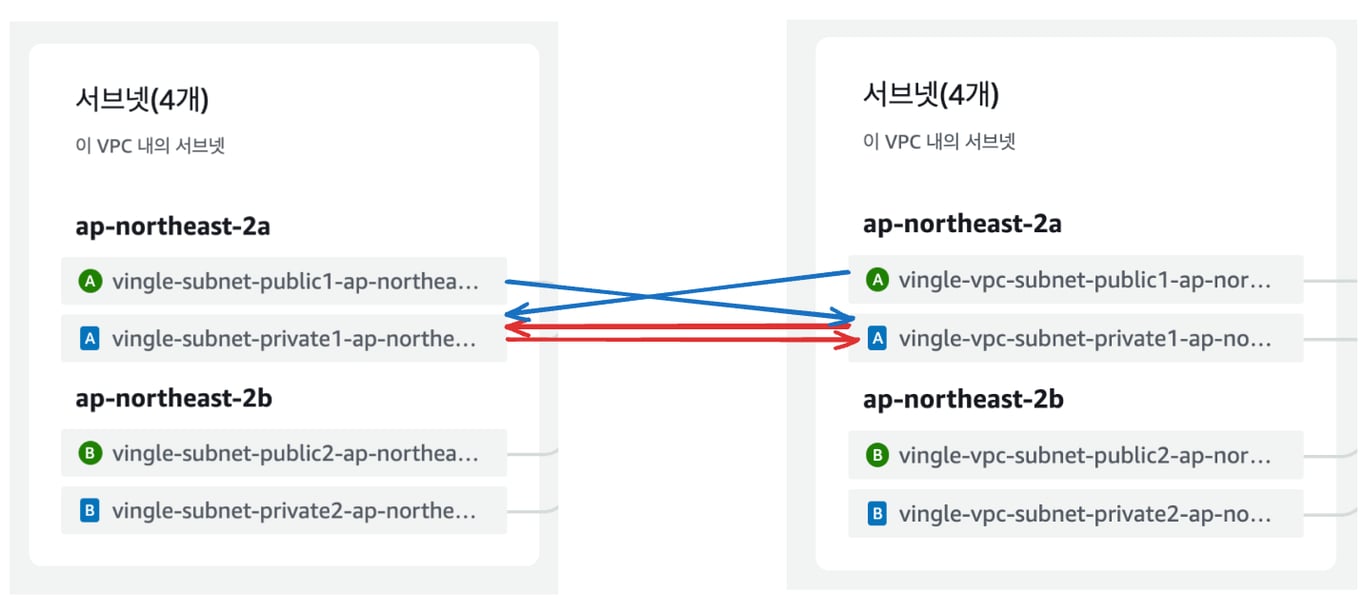
VPC Peering만으로 끝이 아니다.
DB가 속한 서브넷은 VPC Peering 만으로는 접근이 불가하다.
VPC 내의 ec2 subnet에서의 private 접근만 가능하게 설정했기 때문이다.
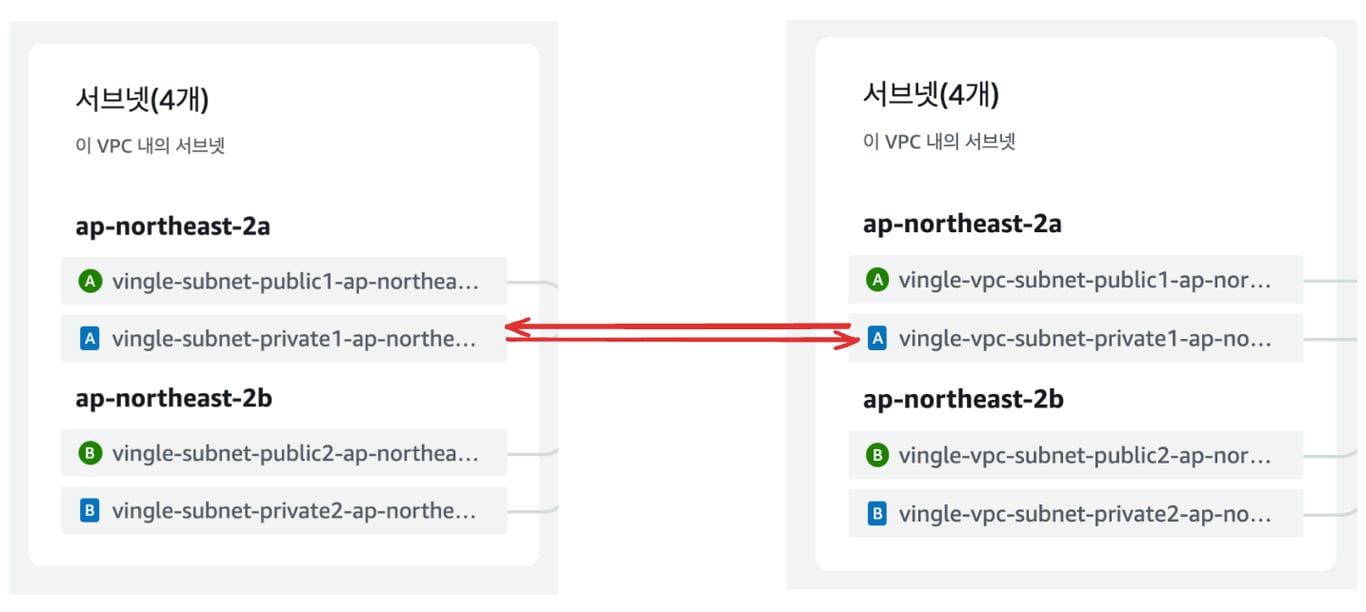
빨간 줄 처럼, private subnet 간의 통신을 열어주어야 한다.
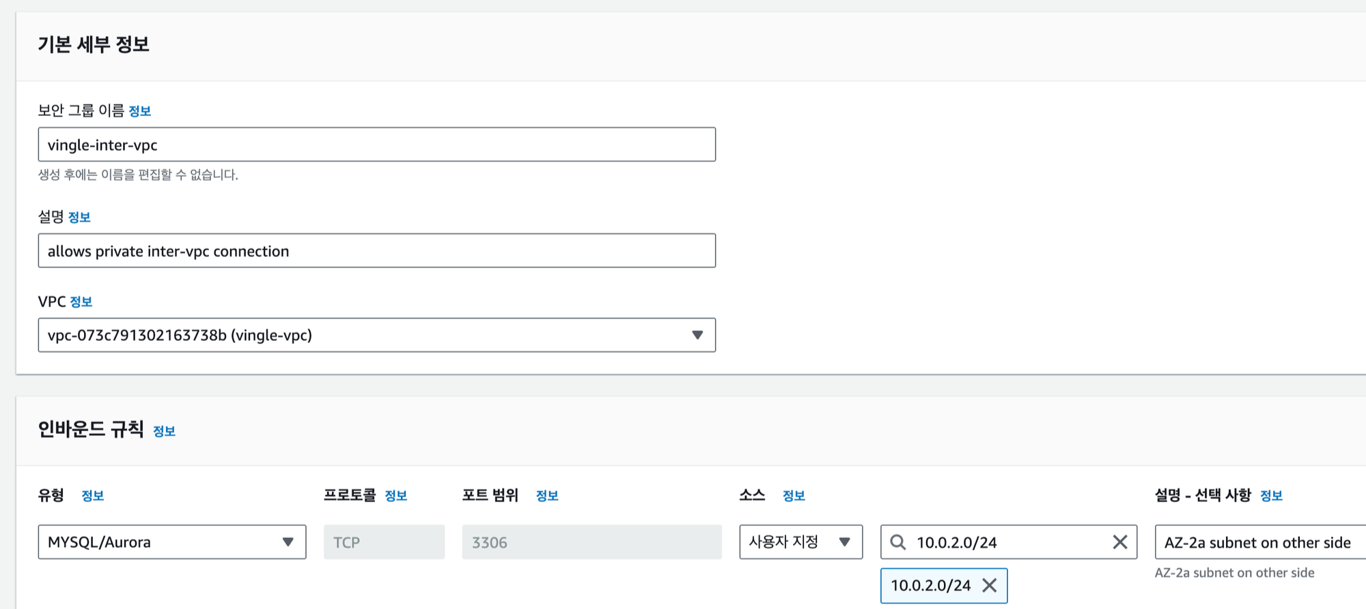
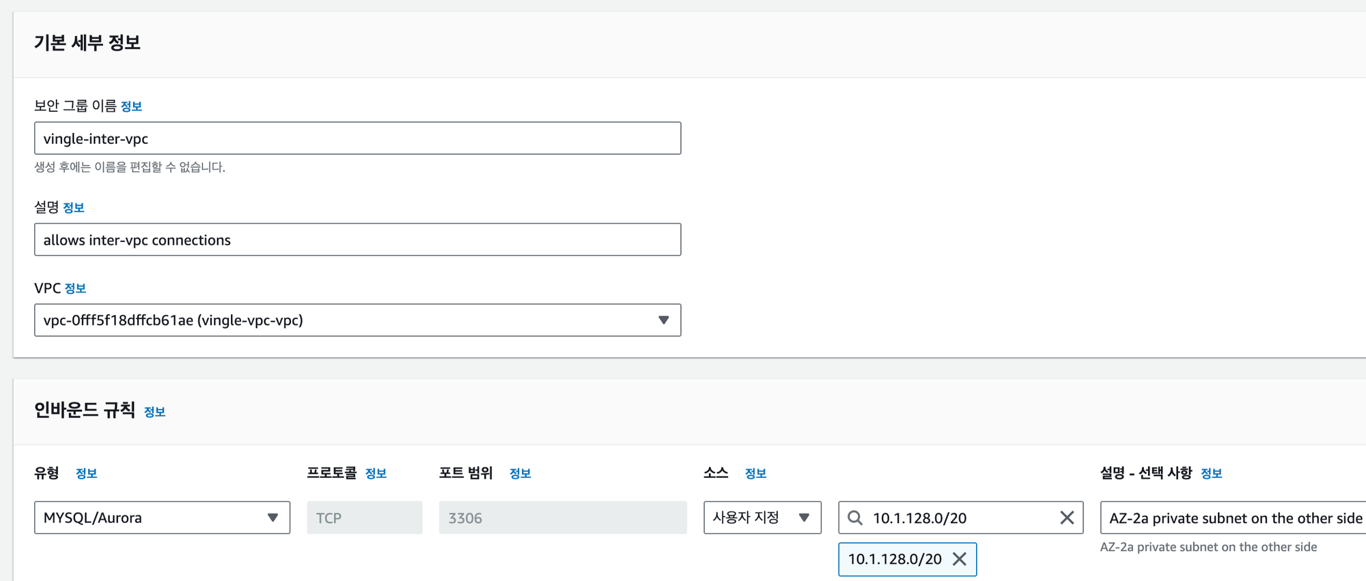
CIDR을 기반으로 보안 그룹의 인바운드 허용 규칙을 만들어준다.
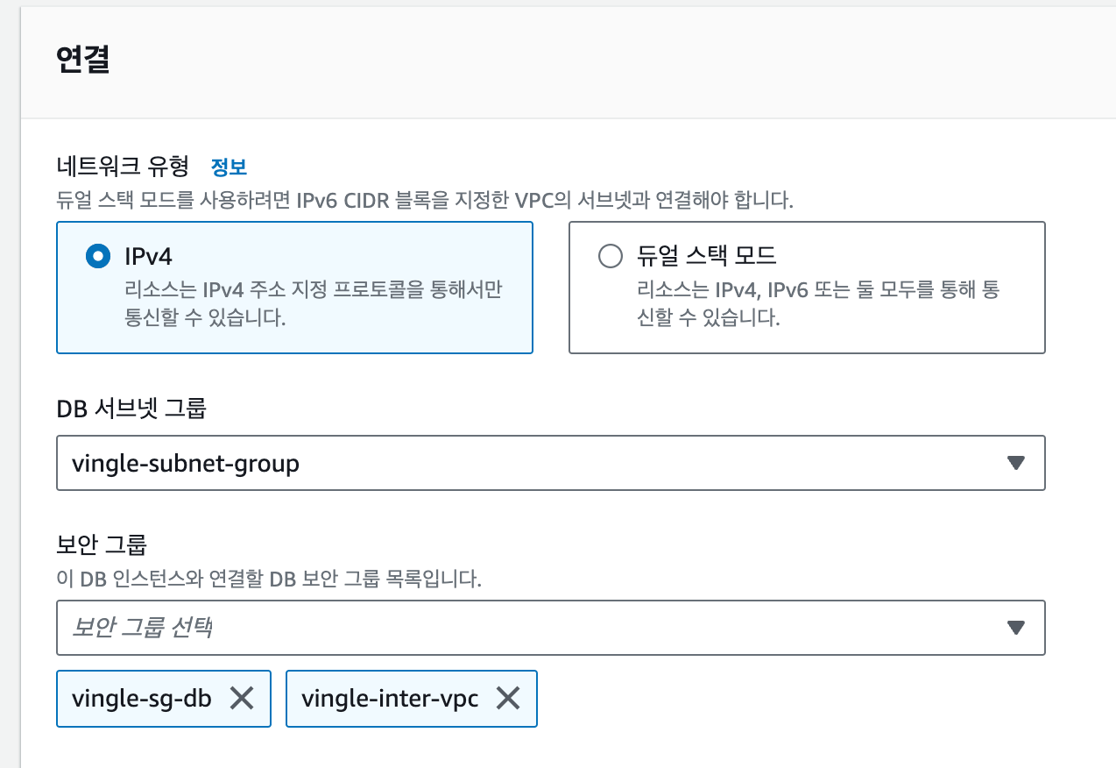
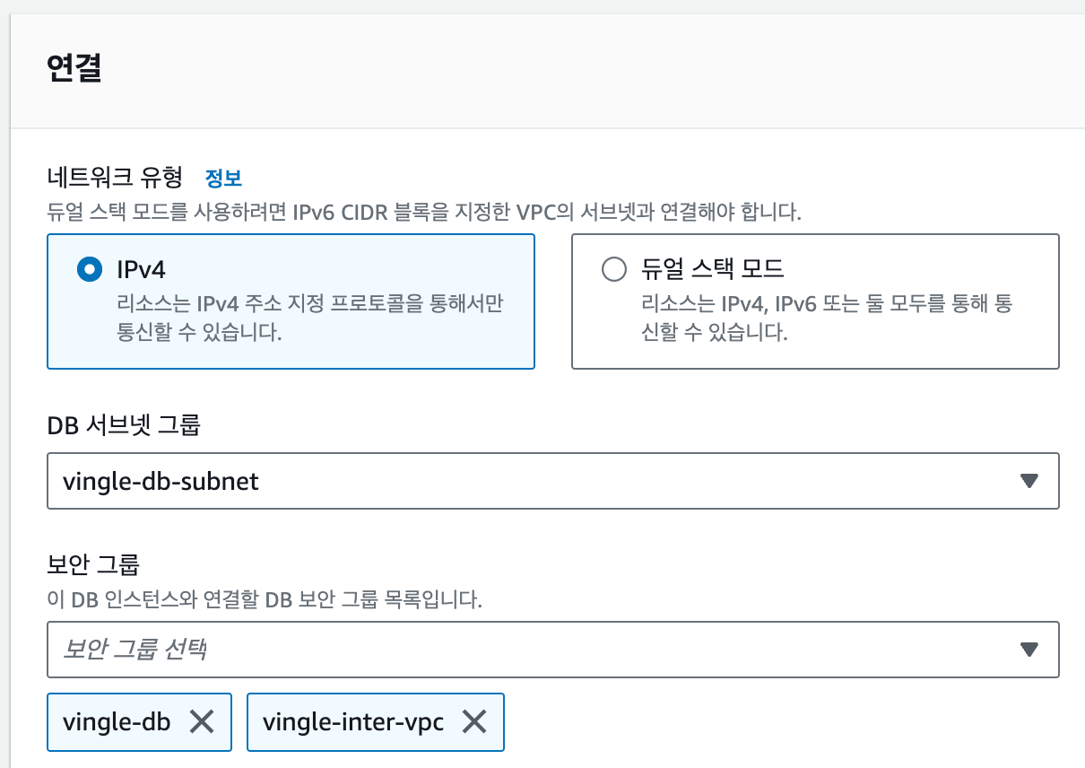
서로의 VPC private subnet의 CIDR을 허용하는 보안 그룹을 만들고, DB 서브넷 그룹에 포함시켜줬다.
(마이그레이션 완료 후 제거 예정)
Master-Slave Replication
이제 진짜로 DB Replication을 걸어보자.
- Source DB의
gtid_executed,gtid_purged


- Target DB(Replica)의
gtid_executed

→ binlog가 상당히 빠르게 purged 되는 모습을 보였다.
지금 위 상황만 봐도 Target DB가 필요로 하는 26211 트랜잭션이 Source DB에서 purged 되기 직전이다.
binlog 순환 정책을 포함해 다양한 글로벌 변수를 찾아보았으나 정확한 원인을 찾진 못했다.


그래서 스냅샷 기반 복제 후 재빨리 replication을 거는 방법을 선택했다 😂
복제에 사용한 명령어는 다음과 같다.
CHANGE REPLICATION SOURCE TO SOURCE_HOST='source_server_host', SOURCE_HOST='3306', SOURCE_USER='repl_user', SOURCE_PASSWORD='repl_user_password', SOURCE_AUTO_POSITION=1, GET_SOURCE_PUBLIC_KEY=1
CALL mysql.rds_set_external_master_with_auto_position ( 'vingle-rds.xxxxxxxx.ap-northeast-2.rds.amazonaws.com' , '3306' , '{replication user id}' , '{replication user password}' , 1 , 0 ); CALL mysql.rds_start_replication;
RDS에서는 super 권한이 없으므로 사전 정의된 프로시저(아래)를 사용했다.
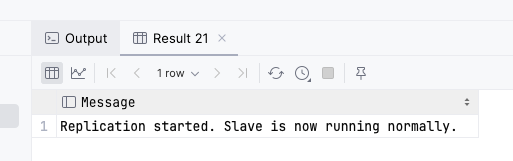
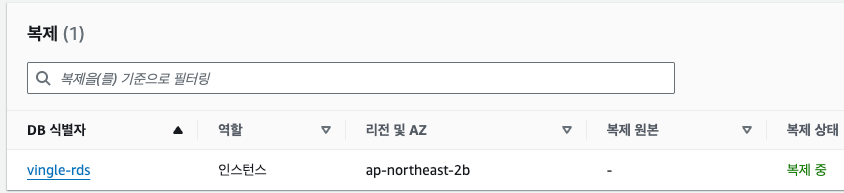
GTID가 자꾸 purged되는 바람에 이 과정을 여러번 반복했지만 결국 성공했다.
나중에 할 땐 AWS DMS를 써보자.

양방향 DB Replication 시작
마침내 새벽이 되었다.
반대 방향(Target→ Source)으로도 Replication을 건다.
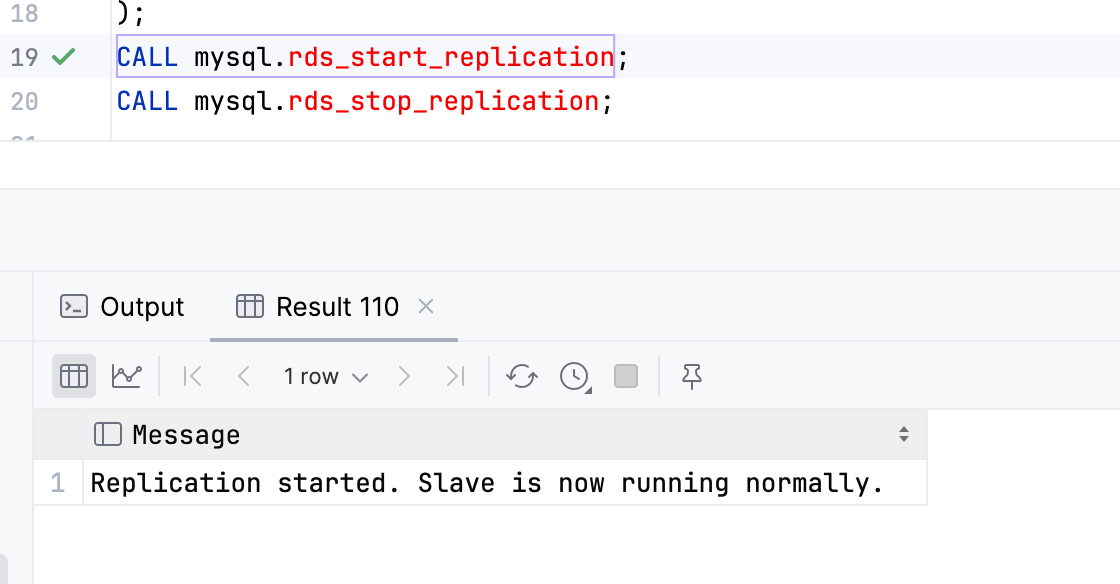
이제 Master-Master Replication이 되었고, 아직까지는 충돌이 없다. (두근세근)
이제 어플리케이션을 전환할 차례.
어플리케이션의 DB 커넥션 전환
목적
Source Infra로 들어오는 트래픽들을 Target DB(Replica)를 사용해 처리한다.
Master to Master Replication을 걸어두고 어플리케이션의 DB 커넥션을 Target DB로 변경하는 방법을 사용한다.
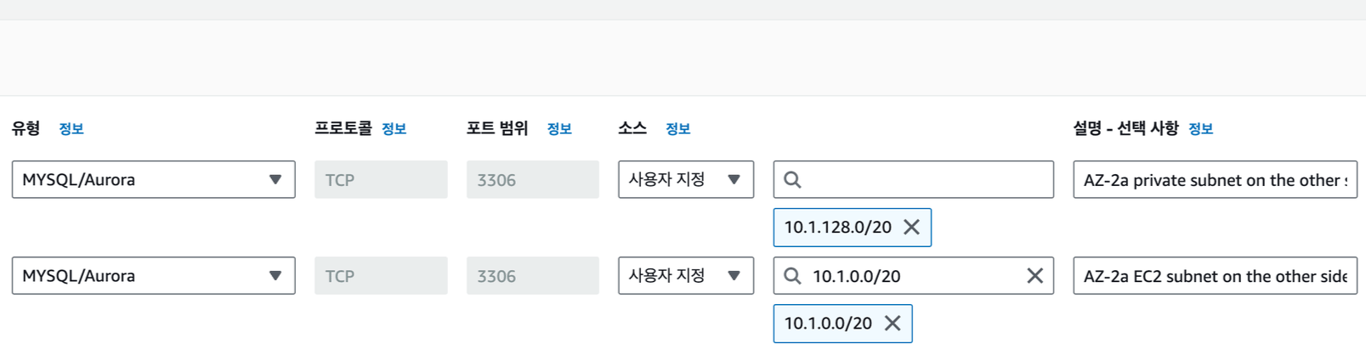
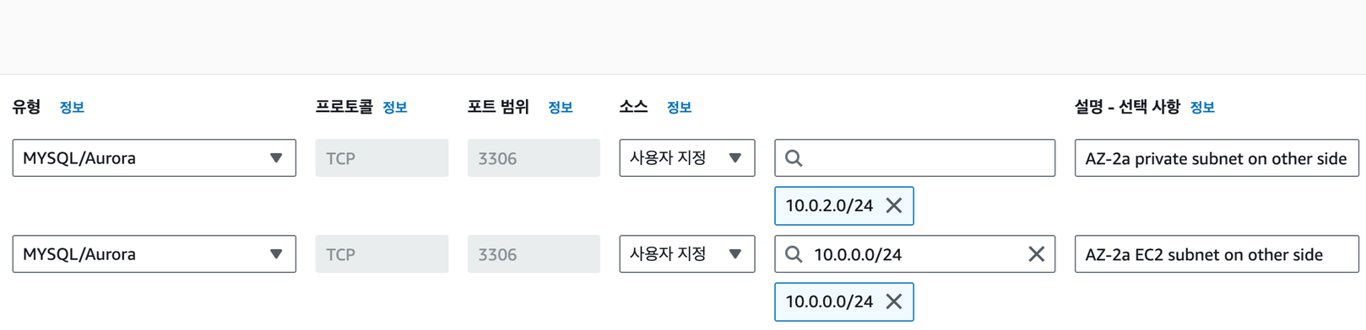
보안 그룹 설정
VPC 간 통신을 걸어두었지만, DB와 마찬가지로 그냥은 접근되지 않는다.
위와 같이 보안 그룹의 인바운드 규칙을 수정해준다.
어플리케이션 설정 수정, 배포

마침내 새 DB를 가리키도록 어플리케이션을 배포했다.
현재 상태는 다음 그림과 같다.
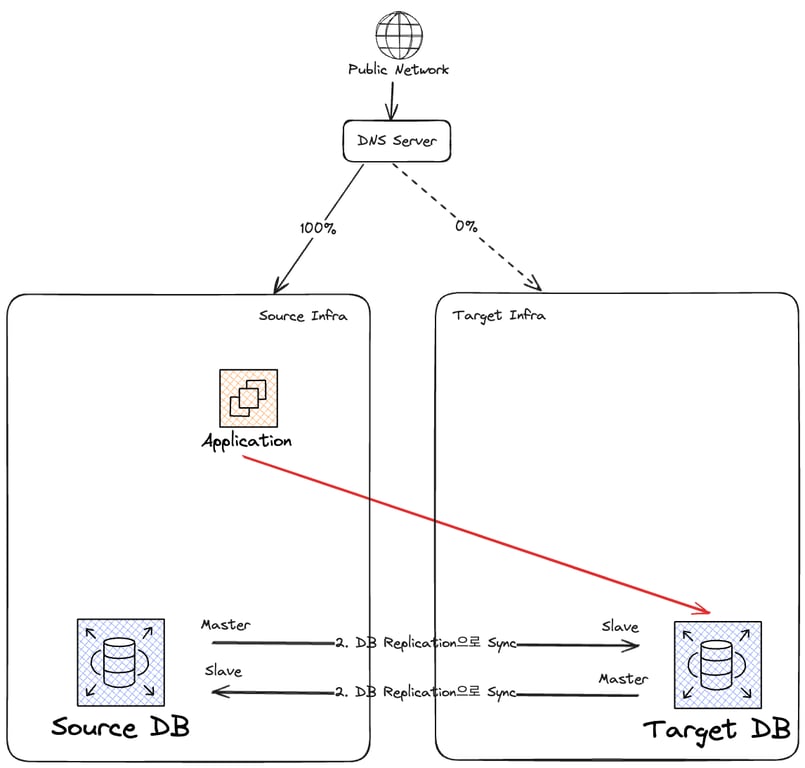
Master-Slave 관계 역전
위에서 얘기했다시피 Master-Master 관계는 오래 유지할 것이 못된다.
언제든 충돌이 발생할 수 있기 때문이다.
Source DB의 Replication 을 중단시켜 Master-Slave 관계를 역전한다.
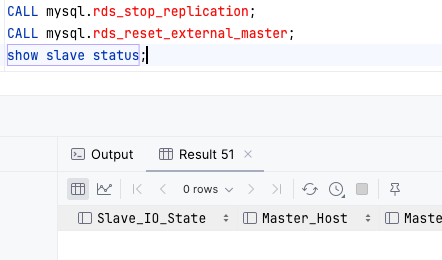
잘 실행되었고, 현재 상태는 다음과 같다.
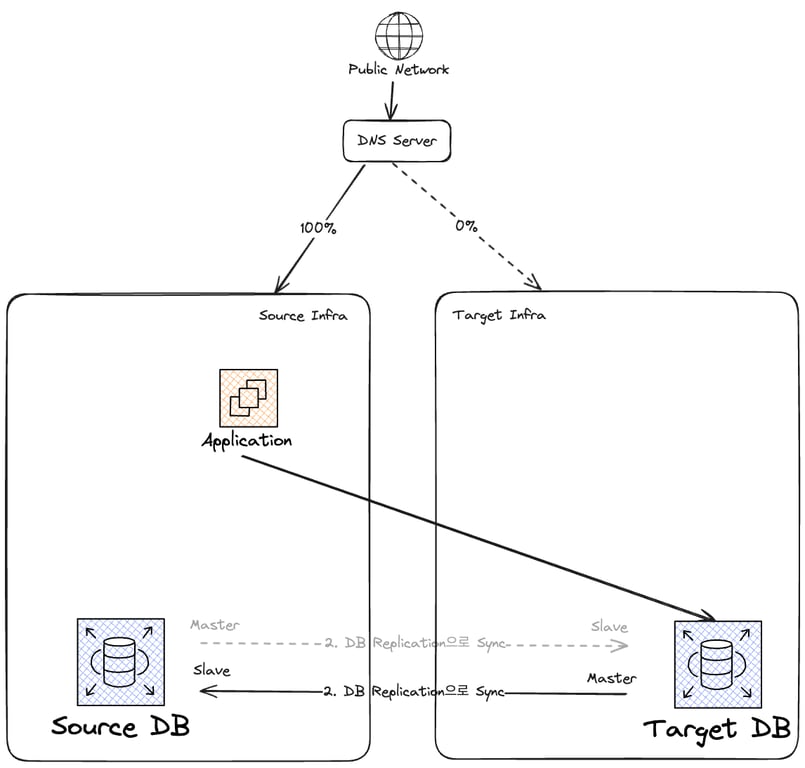
제거를 잘 마쳤고, 이제부터는 Target DB가 Master이다.
새 어플리케이션 실행 + DNS Record 변경
이제 DNS Record를 변경해 트래픽을 점진적으로 새 인프라로 옮긴다.
사실 Route 53을 쓰고 있기 때문에 얘도 옮겨와야 맞지만, DNS Record만 Target Infra의 로드밸런서로 수정하는 것으로 문제를 단순화하겠다.
새 VPC에 어플리케이션 실행
새 인프라(VPC)에도 트래픽을 받아줄 어플리케이션이 필요하다.
서버 인스턴스 구축 및 로드 밸런서 연결 과정은 언급만 하고 넘어가겠다.
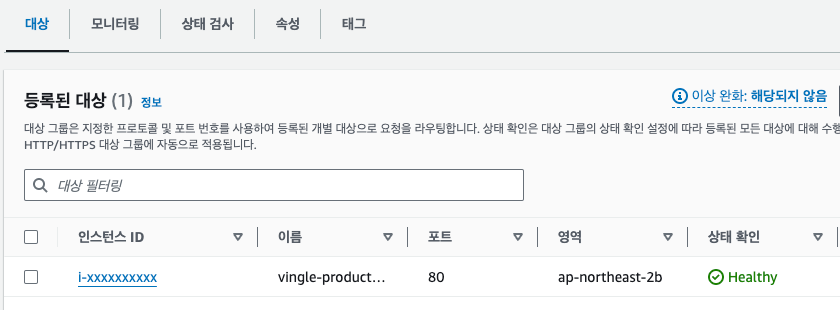
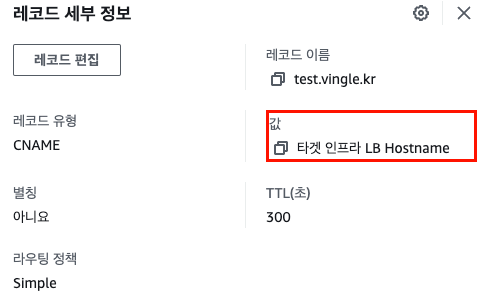
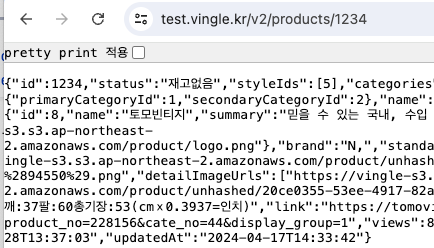
테스트용 서브도메인을 만들어 로드밸런서를 통해 접근이 잘 제어되는 것을 확인했다.
DNS Record 변경
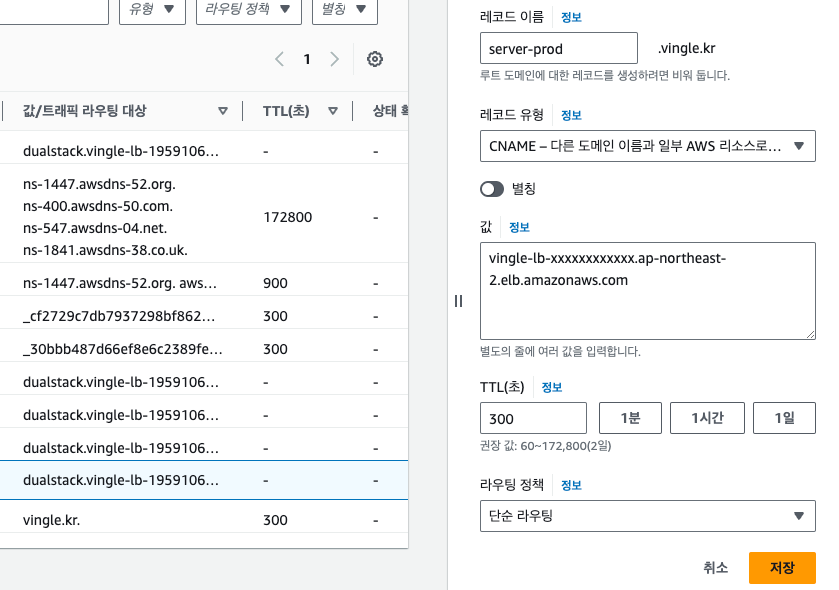
마침내
server-prod.vingle.kr의 레코드를 변경할 시간이다.옛날 계정에 있는 Route 53에 접속해서 CNAME을 새로운 로드밸런서의 주소로 변경한다.

그리고 응답이 새 로드밸런서를 통해서 나가는지 인증서 일련번호를 비교한다.
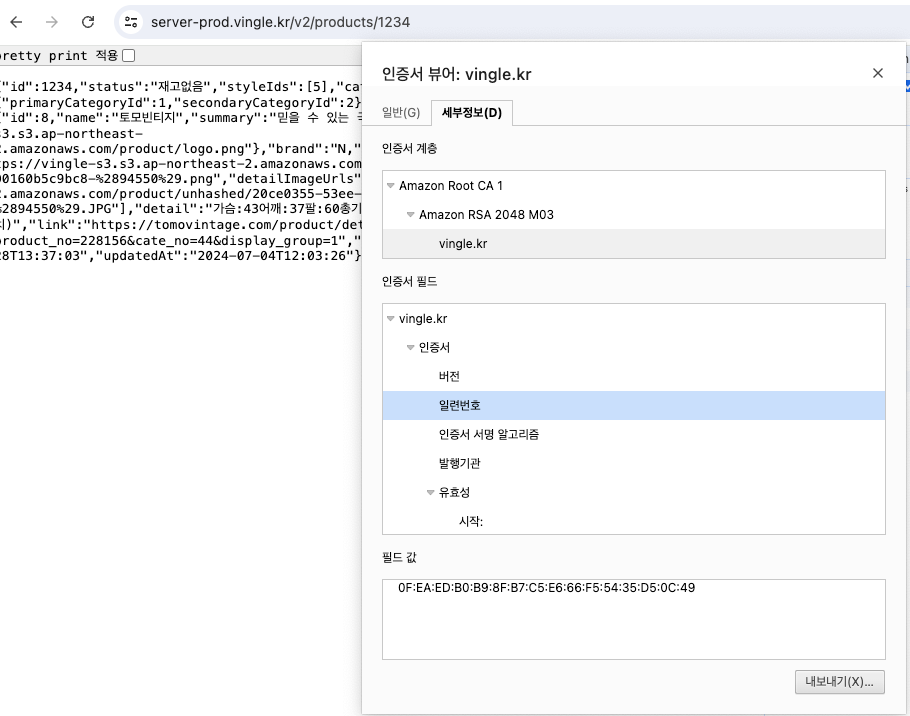
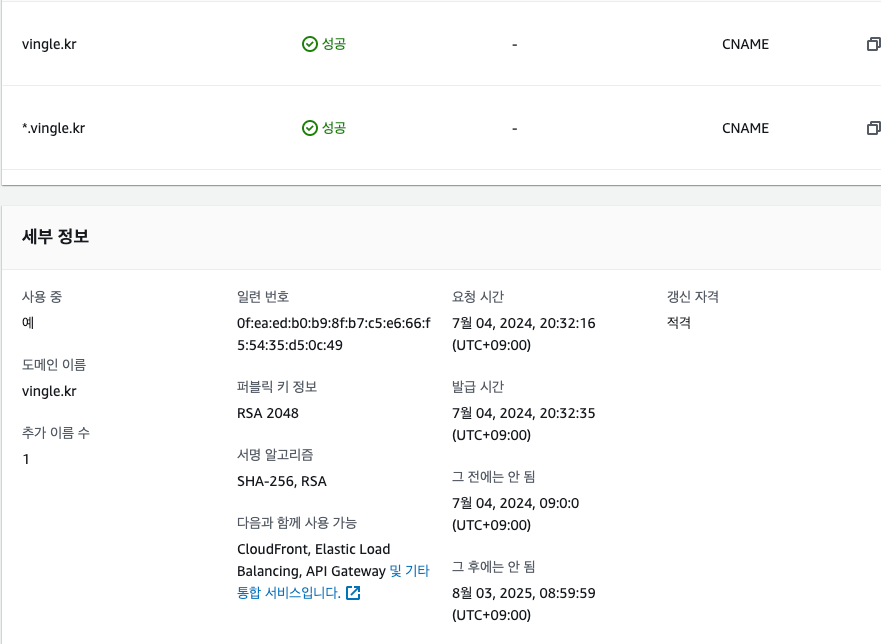
오케이. 잘 변경된 것으로 보인다.
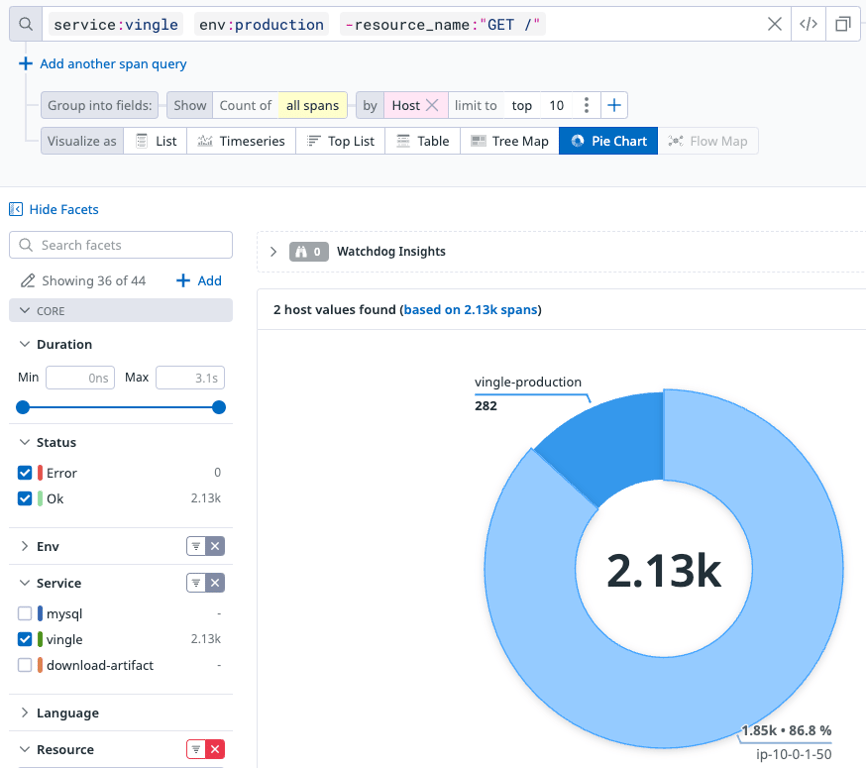
천천히 DNS 레코드 변경이 전파되고 있는 것으로 보이므로, 이제 며칠 정도는 기다리려고 한다.
현재 인프라 상황은 다음과 같다.
기존 인프라 Takedown
DNS Record TTL + a 대기
하루 정도가 지났다.
TTL 이후에 체크해보기도 했었는데, 아래 그래프를 보면 여전히 기존 서버에서 들어오는 트래픽이 있다.
TTL은 내 희망사항일 뿐인 거고, 확실히 희망사항 따위는 가뿐히 무시하는 DNS 프로바이더가 존재하는 것 같다.
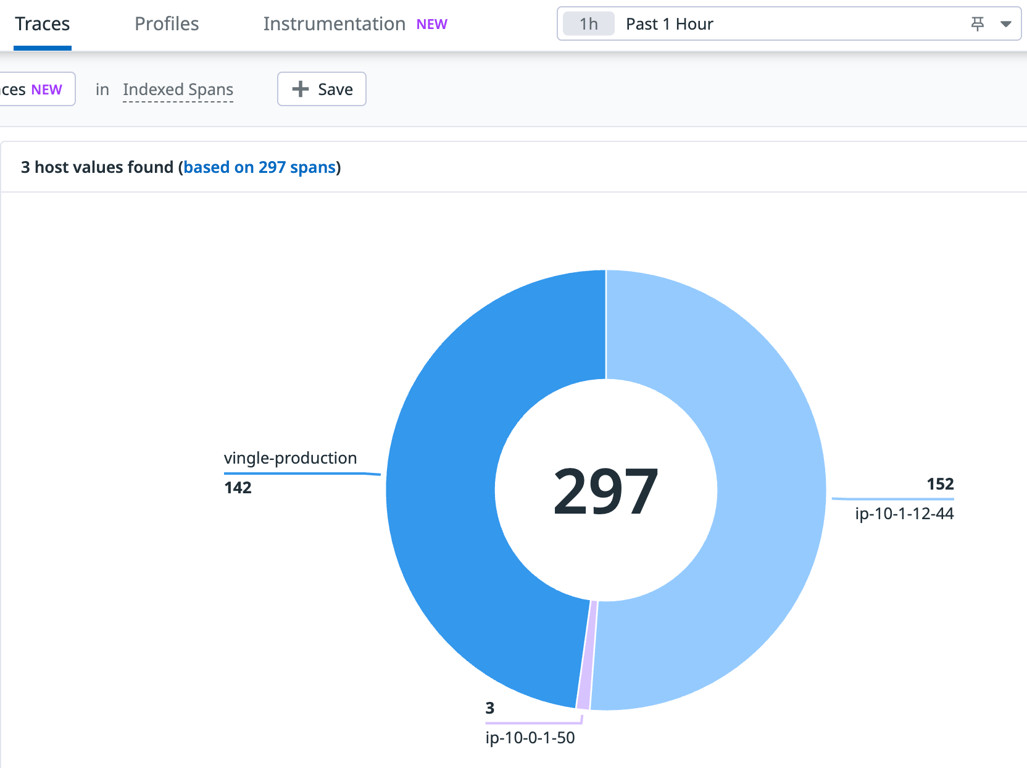
예상했던 바다. 72시간정도는 기다려주도록 하자.
왜 호스트가 3개죠?
인프라를 옮긴 이후 비용으로부터 조금 자유로워졌다.
옮긴 환경에서 무슨 일이 생길지 몰라 서버를 이중화해두었다.
그리고 3일 정도가 지났다.
원래 필요한 시간보다 더 보수적으로 기다렸으니 트래픽이 잘 옮겨갔을 것으로 예상한다.
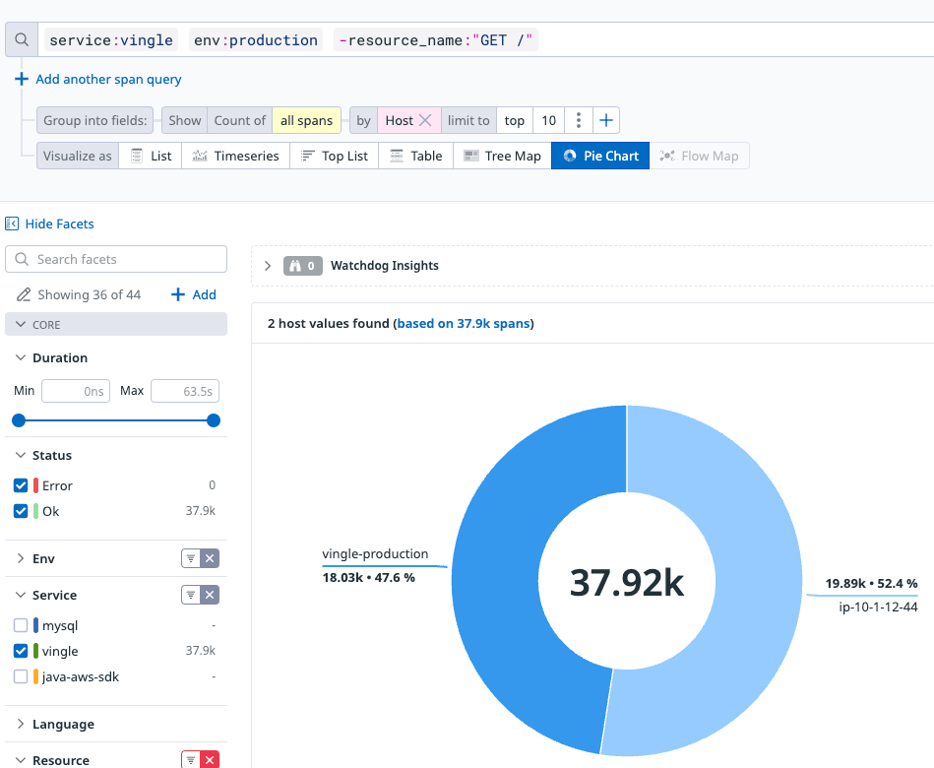
최근 48시간 동안 새로운 서버가 모든 트래픽을 처리했다는 것을 확인했다.
이제 트래픽이 완전히 옮겨간 것으로 보인다.
현재 인프라 상태는 다음과 같다:
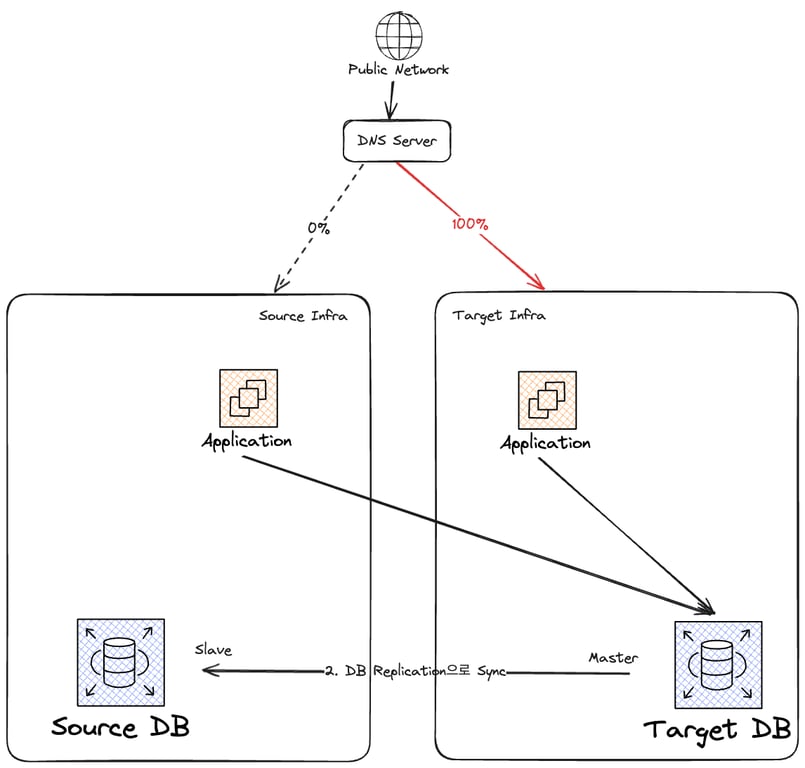
인프라 Takedown
이제 더이상 기존 인프라를 사용하지 않으니, DB Replication을 제거하고, 기존 인프라를 정리한다.
인스턴스 종료는 너무 간단한 작업이라 그림으로만 알아보자:
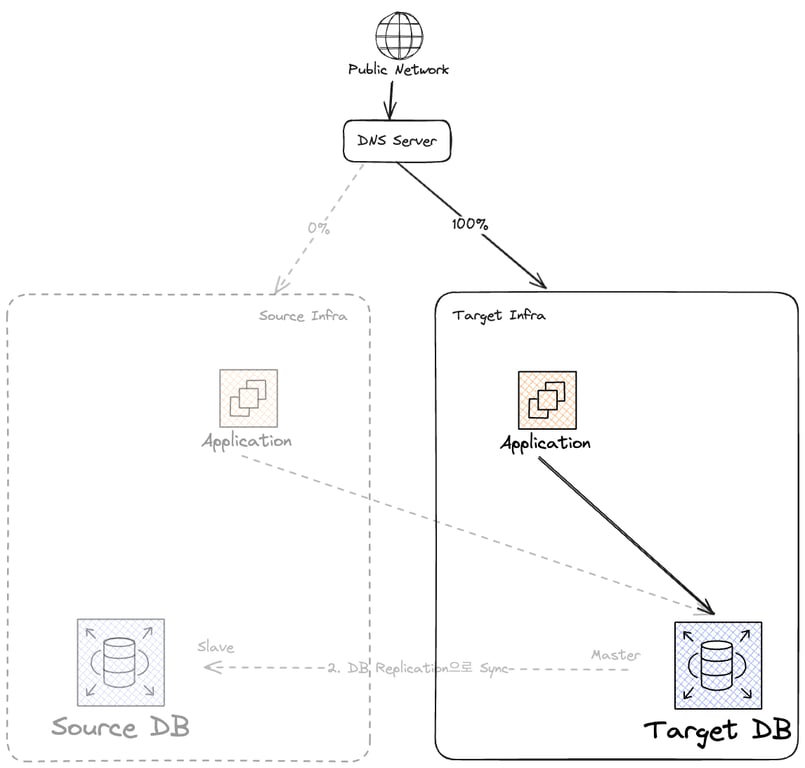
마침내 마이그레이션이 성공적으로 끝났다.
마치며
인생이 계획대로 되는 일은 드물다.
마스터 플랜 같은건 거의 존재하지 않으며, 제어할 수 없는 영역이다.
하지만 계획이라도 있어야 비슷하게라도 흘러가지 않겠는가?
이번 마이그레이션도 다 적지 않은 우여곡절들이 있었지만, 결국엔 비슷하게라도 흘러갔다.
그리고 무중단으로 마이그레이션을 하겠다는 목적도 결국 달성했다.
돌이켜보면 내가 제어할 수 있는 것과 그렇지 않은 것을 정확하게 구분하고, 제어할 수 없는 부분에 대해 최악의 상황을 가정하고 진행하는 것이 안전에 도움이 되었다.
더 큰 인프라—서버가 n대, DB가 n대—는 어떻게 옮겨야 할지에 대한 고민이 과제로 남았다.
 Made with Bullet
Made with Bullet